Architecture
Jube is open source transaction and event monitoring software. Jube is software for real-time data wrangling, artificial intelligence, decision making and case management.
Jube has wider utility; Abstraction values are returned in the real-time response payload, hence Jube can facilitate data wrangling in a Function as a Service (FaaS) pattern. Response payload data is also stored in an addressable fashion, to the effect of improving user experience for advanced analytical reporting, while also reducing database resource \ compute cost.
Jube can be used in a variety of monitoring use cases, but is particularly suited for:
- Fraud or Abuse Detection and Prevention.
- IoT Service Efficiency Assurance.
Jube has only open source dependencies; It runs on commodity Linux Operating Systems and with Postgres databases. The stateless nature of Jube allows for scaling to massive extremes.
Software Architecture
Jube has a highly scalable architecture. Jube performs as much processing as possible in memory in predictably sized thread capacity. Where database interactions are required, it is at a minimum against entities which are optimised to return datasets quickly based on indexed key value pairs using a dedicated Postgres or Redis instance (anything RESP wire compatible in practice, and increasingly Jube would suggest alternatives given improved performance and fallback persistence, such as in KeyDB). Configuration and rule compilation (this is .Net reflection) is done perpetually in background threads so that real-time request processing is not interrupted with computationally expensive language interpretation. Archive storage of the response payload happens asynchronously using internal concurrent queues, sometime after the response payload has been dispatched (and usually in bulk). The Archive payload is comprehensive; When exploited via Postgres binary JSON functions and the functionality inside Jube to promote keys, analytical reporting capability is enhanced to a great extent.
The software is written in C# and is presented as a single binary application, although can be taken to be stateless for the purposes of clustering. While a single binary, Environment Variables are used to enable or disable threads, allocating threads based on desired architecture and work allocation.
Jube is intended to run on a commodity Linux open source infrastructure and has the following software dependencies:
- .Net 8 Runtime.
- Postgres database version 13 onwards (tested on 15.4 but no significant database development to cause a breaking change).
- Optional: Redis version 6 or above (it probably works fine on earlier versions, as the command used are basic. RESP wire compatible implies that it is possible to use KeyDB, DragonflyDB, Garnet or any RESP compliant wire protocol database).
Jube will of course run on Windows, or indeed any platform that is supported by the .Net runtime, however, alternative platforms are not recommended for production use. Windows is not tested. Furthermore, Redis, KeyDB and DragonflyDB, does not support Windows, so Cache options are limited to Postgres Database of Garnet (although there may well be other RESP wire compatible databases that have been overlooked that work on Windows). Unclear why Windows would be a first choice however.
Migration
Jube handles its own database model installation and upgrade, a process known more commonly as Migration. When Jube starts, and after establishing a connection to the Postgres database, a check is performed against a database table called “VersionInfo” to establish what database changes need to be made to harmonise:
select *
from "VersionInfo"
The list of required database changes, determined by cross referencing the table VersionInfo with the available Migrations compiled to the Jube instance, are subsequently executed in the specified order.
Migration requires the following DDL permissions:
- CREATE TABLE.
- CREATE INDEX.
- INSERT.
DDL permissions cannot always assured in production configurations, especially as the implementation becomes more distributed.
Migration can be overridden by Environment Variable:
EnableMigration=False
The default EnableMigration is set to True, and is taken to be the case throughout this documentation.
In the event Migration is disabled, the Fluent Migrator Command Line Runner will need to be executed separately, targeting the Jube.Migrations.dll binary for Postgres 11.0.
Migrations do not exist as a concept for Redis as this is a schemaless Key \ Value Pair in memory database where Keys are upserted (inserted or updated on existence). Henceforth, Redis does not have a schema, although values do have a very specific structure native to Jube.
Embedded Kestrel HTTP Web Server
The Jube instance exposes an embedded web server by the name Kestrel. As long as the application started without error - itself a simple matter of ensuring the .Net runtime and Postgres database connection - then HTTP requests can be made.
All HTTP requests will be targeted at the Kestrel webserver, and include:
- Static content such as javascript files and images not subject to authentication.
- Page HTML content which is subject to authentication, with the exception of the authentication page itself. HTML content and static content is entirely dependent on API controllers.
- The API controllers which are subject to authentication, except for the authentication controller itself and a public facing invocation endpoint. The API is a variety of endpoints that are parametrized as either JSON post bodies, and less frequently querystring values. The API is documented via Swagger at https://localhost:5001/swagger, once the Jube instance is running and responding to HTTP requests. It follows that any interaction that can be achieved in the user interface, can also be achieved via API directly, subject to authentication.
Authentication relies on a standard implementation of JSON web tokens stored in a HTTP header called authenticate, or a http cookie called authentication, which must always be present except for unauthenticated resources.
The JSON web token encrypts using Environment Variables:
JWTValidAudience=http://localhost:5001
JWTValidIssuer=http://localhost:5001
JWTKey=ExtraSuperDuperSecretKeyCreatedOnFirstStartup
| Value | Description |
|---|---|
| JWTValidAudience | The server domain that is allowed the token. |
| JWTValidIssuer | The server domain that issued the token. |
| JWTKey | The encryption key for the token. This key is created randomly on first instantiation of Jube, but can be changed by updating the Environment Variable. |
Notwithstanding a stateless architecture, the token contains a single claim type of Name (http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name), which will contain only the username (e.g. Administrator).
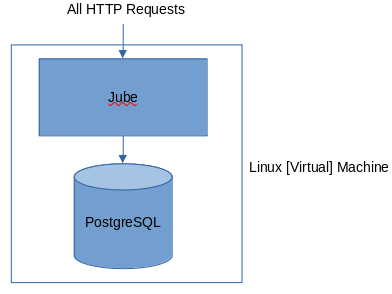
HTTP Undistributed Installation
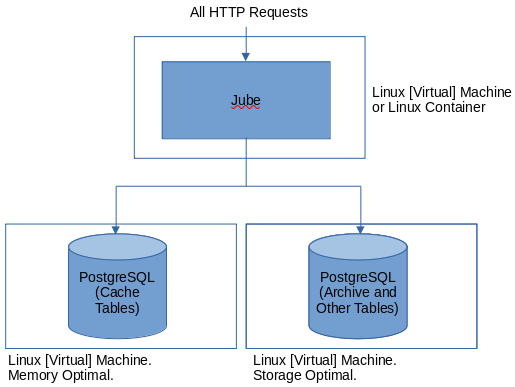
An Undistributed installation with either Postgres Database or Redis Cache is the quick start:
It is not suggested that the cache be on the same server (Containers or Virtual Machines in likelihood) as the Jube instance, hence alternatively:
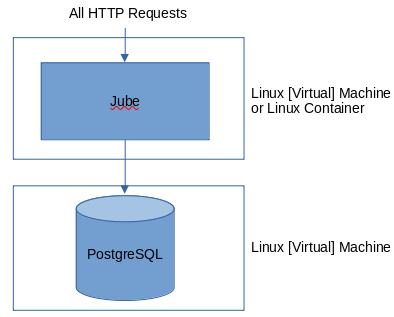
To the extent that it is thought by the technical end user that Containerisation differs from lightweight Linux Virtual Machines, it is fully supported.
Environment Variables required by a Jube instance are passed aa an operating system Environment Variable (the default way to pass invocation values to a container image).
In an undistributed installation there is only a single Postgres Database for housing the cache, which is far from recommended, instead at a minimum Cache should be offloaded as follows.
HTTP Undistributed Installation with Cache Offload
Quick start is a single Environment Variable being updated for the connection to a Postgres database:
ConnectionString=Host=?; Database=?;Username=postgres; Password=?;Pooling=true;Minimum Pool Size=0;Maximum Pool Size=100;
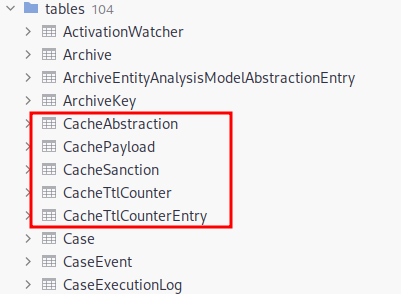
Quick start assumes a single database containing all objects required by the Jube instance. Tables that are prefixed Cache in the database are intended for very fast moving data, specifically high throughput transactional writes and indexed cached reads.
Redis is default in place of Postgres as the cache, simply set Environment Variable to true and pass the Redis connection string (simply the IP of the remote Redis Cluster):
RedisConnectionString=?
Else disable as:
Redis=False
Cache has extreme performance demands and should be entirely uncontested when real-time tolerances are demanded. Furthermore, cache should be forced almost entirely into memory, which in the case of Redis is the only option anyway. Ensuring that cache has an uncontested in-memory habitat is not all that achievable without offloading these entities to a separately sized and memory optimal process and server (this is complicated by Redis being a single thread, which makes alternatives such as DragonflyDB, KeyDB and Garnet increasingly attractive, offering better performance and greater consolidation).
In the case of Postgres, Cache tables can be offloaded to a separate database by adding another connection as Environment Variable:
CacheConnectionString=Host=?; Database=?; Username=postgres; Password=?;Pooling=true;Minimum Pool Size=0;Maximum Pool Size=100;
Be sure to set Redis to false to enable the Postgres cache:
Redis=False
In the case of Redis, given default, simply identifying the server already set out above, and as follows:
RedisConnectionString=?
In the case of Redis being used as a cache the installation by its nature will be entirely in memory and writing to disk, which is asynchronous in the form of an Append Only Log (AOL), exists for recovery only. In memory databases like Redis need meticulous capacity planning and monitoring, so not to allow for a situation where memory runs and and keys are evicted (a disastrous situation for Cache integrity). Key eviction is so problematic, it is suggested to consider KeyDB and its flash capability allowing for fall back to flash, not to mention the benefits of multi threaded performance which Redis has fallen far behind on.
In the case of Postgres being used as cache, the server responsible for hosting the Postgres database containing Cache tables should be memory optimised, such that Postgres and the file system can optimise much of the data into memory, falling back to very high performance disks, thus having the effect of achieving consistent real-time response times. It is possible to disable the WAL (Write Ahead Log) at the table level which has the effect of a non-durable and in-memory solution, given the table being ‘warmed’ into memory (pg_prewarm). No such issues exist in Redis, but in memory databases bring about their own set of considerations which are outside he scope of this document. In the absence of CacheConnectionString Environment Variable, the incumbent ConnectionString Environment Variable is used, henceforth the default is cache tables to reside alongside the other tables. Migrations will be executed independently and comprehensively for both databases.
HTTPS Load Balanced Distributed Installation with Cache Offload
A Jube instance is designed in an entirely stateless manner such to sit behind a standard HTTP load balancer. In HTTP load balancing, requests to the load balancer are sent to different backend servers in rotation, allowing for horizontal scalability. There is no session state within the Jube instance for any HTTP interaction, hence server affinity is not required (state is offloaded to the Postgres databases where required):
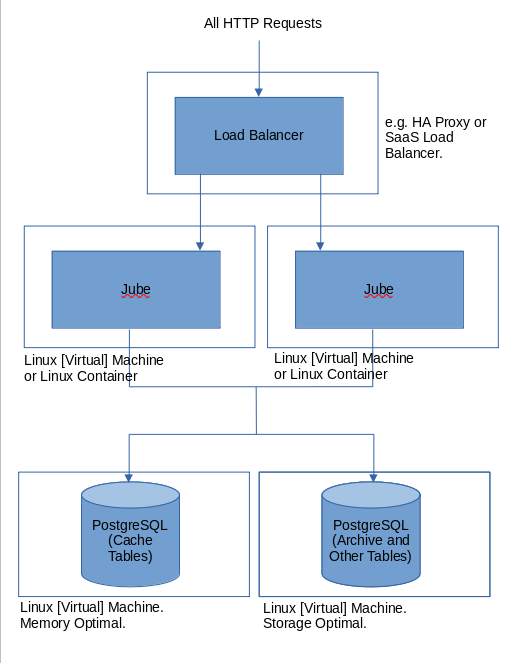
There is no specific configuration required of a Jube instance to achieve load balancing, with the configuration being offloaded to the load balancer itself.
A Jube instance exposes a self hosted and embedded HTTP web server called Kestrel which supports SSL \ HTTPS schemes, however by default the certificate is self signed and intended to secure internal transport only. In the event a Jube instance is made available over a public or corporate network, it is advisable to implement a reverse proxy or load balancer for the purposes of offloading the SSL \ HTTPS schemes, even if there exists only a single backend server. While the Kestrel embedded HTTP web server can support SSL with own certificates, it is not commonly used to support own SSL \ HTTP schemes in production use.
RabbitMQ Load Balanced Distributed Installation with Cache Offload
In addition to HTTP interfaces to a Jube instance, RabbitMQ (supporting AMQP protocols) can be used for model invocation. The purpose of the RabbitMQ is to provide the following additional capabilities:
- The response payload available otherwise by HTTP response is emitted on an exchange called ‘jubeOutbound’ that can be subscribed to by consumers as required. This may takes place even if model invocation has taken place via HTTP.
- The request payload otherwise sent by HTTP request can be placed into a queue called ‘jubeInbound’ along with certain routing headers that would otherwise be in the HTTP URL stub.
- Activation Rule matches are sent to an exchange called ‘jubeActivations’ for consumption by the Watcher in the user interface, but can be otherwise subscribed to by consumers as required (noting this data is largely a reduced version of what is available in jubeOutbound exchange). If RabbitMQ is not enabled, the same effect is achieved for supporting Watcher functionality by Postgres notification or polling the Activations table in the database.
- Notifications dispatched as a consequence of an Activation Rule match can be placed to a queue called “ jubeNotifications”. If RabbitMQ is not enabled, the same effect is achieved for supporting Activation Rule Match Notification functionality by polling the Notifications table in the database.(notifications sent via the case management system are synchronous).
RabbitMQ is not enabled by default:
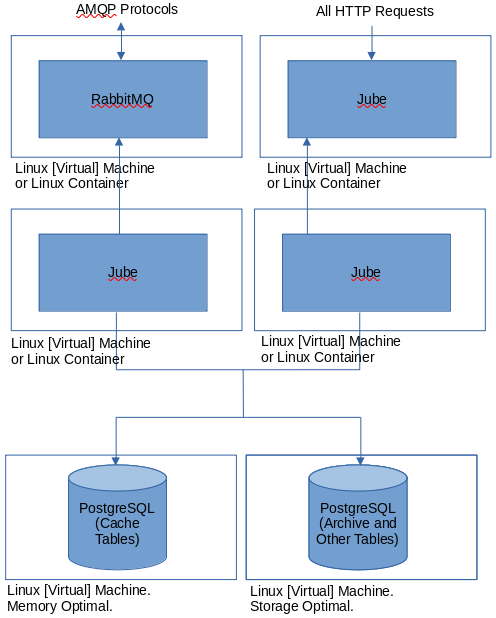
To enable RabbitMQ, the following Environment Variable needs to be updated:
AMQP=True
AMQPUri=amqps://hostname:secret@cow.moo.cloudamqp.com/hostname
| Value | Description |
|---|---|
| AMQP | True or False to signify that connections should be established via the AMQPUri connection string to the RabbitMQ server or cluster. |
| AMQPUri | The connection string to the RabbitMQ server. |
HTTPS Highly Available Load Balanced Distributed Installation with Cache Offload and Component Isolation
Jube in a single process, but given the stateless nature it can be clustered and arranged in a highly available manner. Given the comprehensive nature of the Jube instance, it is foreseeable that certain services, which would be background threads consuming resources, may not be used despite being instantiated by the default Environment Variable configuration (although they will be wait sleeping if not not in use, so the effect is minimal).
The following diagram shows how the Jube instance can be arranged in a highly available fashion as backend servers to a load balancer, yet also the extent to which services can be allocated to individual servers:
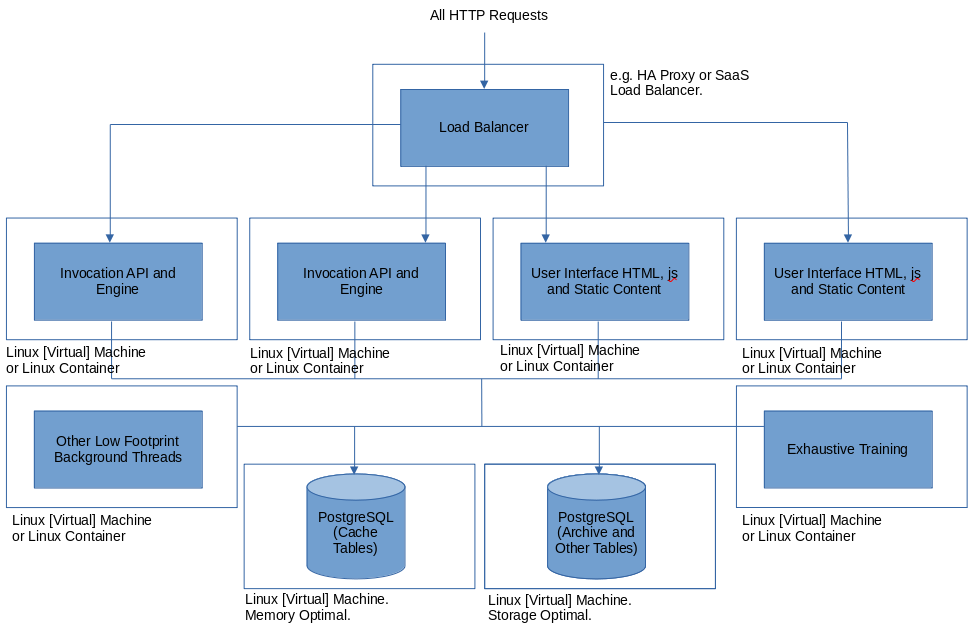
The above example would be overly distributed for most use cases, but serves to explain concepts.
The instances are provisioned for their purpose using Environment Variables. In the above diagram there is provisioning for the following:
- Invocation API and Engine.
- Other CRUD type API functions for User Interface HTML, js and Static Content.
- Other low footprint threads.
- Exhaustive training.
- Reprocessing.
- User Interface HTML, js and Static Content.
Although presented in more detail in subsequent sections of this documentation the real-time model data is processed via either a HTTP endpoint or an AMQP queue called jubeInbound.
In the case of the invocation HTTP API endpoint, there is no formal JSON Web Token authentication, and is instead intended for integration, being restricted by IP filtering or network security more generally. The default is that public user of the Invocation HTTP API endpoint is allowed, hence an Environment Variable change is not required by default. Public invocation of the Invocation HTTP API endpoint can be restricted by updating an Environment Variable as:
EnablePublicInvocationController=False
Model processing relies on a complex set of background threads collectively referred to as an the engine.
While the embedded Kestrel HTTP web service is responsible for processing requests, it is transposed to the engine.
AMQP meanwhile is handled directly via the engine.
Generally speaking, all but the most rudimentary user interface serving requires the engine to be enabled in the Environment Variable. The engine is enabled by default but can be disabled by Environment Variable:
EnableEngine=False
Several threads are instantiated by the engine as default, but can be disabled from their default via Environment Variables:
EnableSanctions=False
EnableReprocessing=False
ReprocessingThreads=1
EnableExhaustiveTraining=False
EnableCacheIndex=False
EnableCasesAutomation=False
EnableSearchKeyCache=False
EnableTTLCounter=False
EnableNotification=False
| Value | Description |
|---|---|
| EnableSanctions | Responsible for loading and serving sanctions check requests on the instance (in both model processing and direct request via HTTP). |
| EnableReprocessing | Responsible for reprocessing data from the archive though the models in a similar manner as real-time. Useful when new model configuration has been put in place and data needs to be modified. It is extremely intensive. Has provision for concurrency between instances and multiple ReprocessingThreads. |
| ReprocessingThreads | The number of threads allocated to reprocessing. |
| EnableExhaustiveTraining | Responsible for training anomaly detection and neural network models. A computationally expensive process and care should be taken to isolate from real-time processes for risk of degradation of real-time model invocation response time. |
| EnableCacheIndex | Responsible for creating indexes in the cache tables. The process is computationally immaterial and there are some checks made for index existence, henceforth, some concurrency and high availability is allowed for (but it is inelegant). |
| EnableCasesAutomation | Responsible for case scheduling, specifically the reopening and closing of cases on lapse of expiry date. This routine has poor concurrency and it is suggested that there be only a single instance at this time. |
| EnableSearchKeyCache | Responsible for the background processing of Abstraction Rules designated as being cached (this is aggregations having been precomputed rather than being online in the real-time model invocation). There may only be a single instance as there is no concurrency available. |
| EnableTTLCounter | Responsible for the background maintenance of TTLCounters. There may only be a single instance. |
| EnableNotification | Responsible for the background dispatch of Notifications, either by connecting to RabbitMQ or maintaining a polling thread against a Notifications in memory concurrent queue. |
| CachePruneServer | Responsible for the deletion of data from CachePayload and CachePayloadLatest entities. |
| WaitCachePrune | The time in milliseconds between the cache being pruned for expired payload and latest entries. |
Such is the reliance of Jube upon the Kestrel HTTP web server, there is no means to disable it, henceforth - and subject to JSON web token header authentication in many cases - User Interface HTML, js and Static Content and other CRUD type API functions. will always be available.
Database High Availability Considerations
A Jube instance is stateless however the platform application itself would be stateful given a dependence on the database.
The database contains tables that provide for state in several areas:
- Cache tables intended to provide state in the transactions or events, which is doubtless the most critical stateful aspect, given that Jube is most likely integrated in support of realtime decision making.
- Permission tables to secure access to resources given the username available in the JSON Web Token Name Claim (http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name).
- Session variables specific to the user experience in Case Management.
High availability of the Postgres database is outside the scope of this documentation, as the manner in which high availability is achieved is standard and generic. Postgres has become a commodity database provided by major cloud providers (AWS, GCP, DigitalOcean and Linode) and in all instances have the aforementioned high availability natively configured.
The suggested approach to high availability of the database is to use a standby server alongside streaming replication functionality native to Postgres. One or more standby database when sat behind middleware such as PgPool2 is commonly known as a database cluster.
It is suggested that storage be offloaded to highly durable external storage in the case of archive and highly performance local storage in the case of Cache. WAL should be written to separate high performance disks and asynchronous write usage maximised. In the context of resilient failover with disks offloaded, the failure of the Postgres instance is quite implausible, the implementation can be scaled up, rather than out which is both easier and cheaper.
There are technologies available to achieve Active \ Active, or Multi Master databases, but they tend to be brittle and latent. Unless entities within transaction or event data are very slow moving, Active \ Active nodes is not a suggested approach.